真机采集太贵太慢
遥操、穿戴设备或专业动捕依赖设备排期和人工操作,难以快速覆盖大量任务与场景。
客户痛点
遥操、穿戴设备或专业动捕依赖设备排期和人工操作,难以快速覆盖大量任务与场景。
监控、演示、网络视频里有大量人类操作,但缺少 3D 标注和坐标系统,无法直接进入训练链路。
每个新任务都重新搭建采集系统,会让数据积累变成一次性项目,而不是可复用资产。
交付流程
momax.ai 不只是输出可视化结果,而是围绕客户任务交付可计算、可筛选、可接入训练管线的数据资产。

你提供
客户提供现有视频、指定任务场景,或由我们协助设计轻量采集方案。
MOMAX 引擎
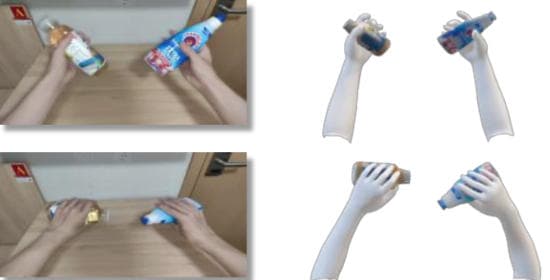
恢复全身姿态、手部状态、物体 Mesh、场景几何和时间同步关系。

你拿到
导出策略轨迹、接触事件、相对位姿、VLA 标注和任务评测信号。
采集方案
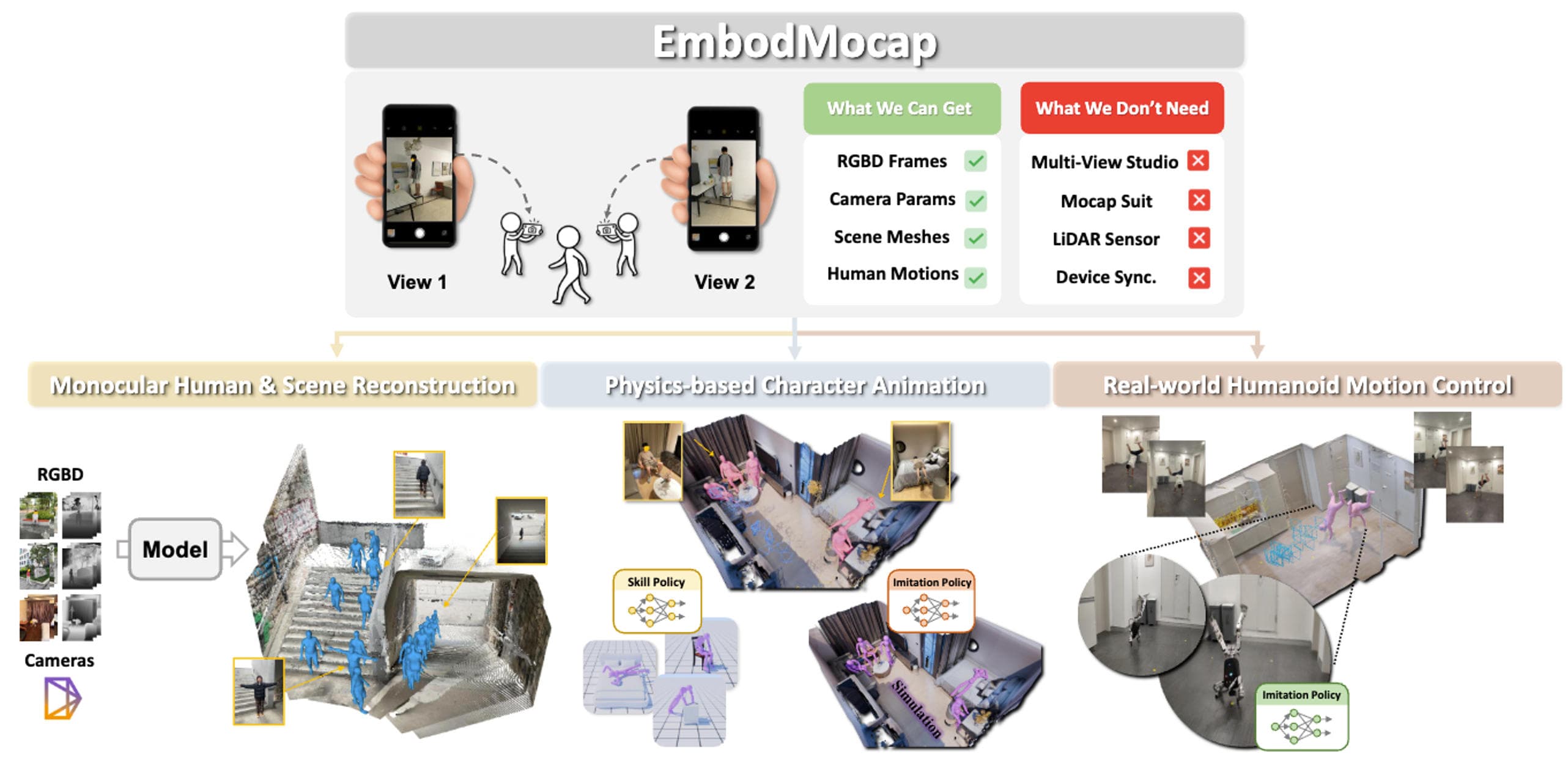
同一套数据引擎可以接不同输入源:高精度动捕用于标定质量,多目/第一视角视频用于产品级数据生产,单目或存量视频用于规模化扩展。
同一套数据引擎可以接不同输入源:高精度动捕用于标定质量,多目/第一视角视频用于产品级数据生产,单目或存量视频用于规模化扩展。
 最高精度
最高精度影棚或实验室环境,适合高精度全身动作、手物交互和核心任务基准数据。
适合:高精度机器人数据、人物交互真值
 产品级精度
产品级精度第一视角与第三人称 RGB 相机组合,无需穿戴传感器,支持规模化现场采集。
适合:规模化数据生产、loco-manipulation 数据
 零额外硬件
零额外硬件使用客户已有视频或互联网素材,高效扩展任务覆盖与长尾动作分布。
适合:大规模 VLA / 世界模型预训练
技术验证
我们把重建结果组织成下游可消费的状态、事件和轨迹,并用 Sim2Real 链路验证数据对机器人训练的实际价值。
Sim2Real
多目视频方案已接入仿真与真机验证链路
统一坐标系
全身、手、物体和场景共享同一空间表达
多源输入
支持动捕、多目、第一视角、单目与存量视频
任务级输出
交付轨迹、接触、位姿、质量指标和训练接口
场景覆盖
当前重点覆盖机器人学习中最需要高质量状态监督的手物交互和固定工位任务,同时保留向全身运动、场景交互和多人互动扩展的技术路径。



技术延展
团队同时具备人形机器人物理交互控制、虚拟角色风格化动作生成和 3D 角色驱动能力,可支持社交机器人表达动作、数字人风格化驱动等合作场景。